In this blog post I’m going to show you how to get started with geospatial search with Elasticsearch, using the official and fantastic .NET client for Elasticsearch, NEST. An example like this is best served with real data, so given this post was written from Australia, we’ll use the State Suburbs (SSC) from 2006provided by the Australian Bureau of Statistics as the data of interest; it's provided in ESRI Shapefile format and contains a collection of all the Australian Suburbs, each with a name, code and geometry; We’ll need to extract each suburb from the Shapefile and serialize them to a format that can be persisted to Elasticsearch and so that we can query them.
TL;DR
I’ve put together a demo application to illustrate geospatial search using Elasticsearch and NEST..
Index all the things

Elasticsearch is a popular open source near real-time distributed search engine designed for large scale search. It's built on top of Lucene and designed to horizontally scale as the demands of search and volume of indexed data increase. How well does it scale? Well, you need only look at examples such as Github to get a feel for the amount of data that can be indexed and queried; back in 2013, Github was using Elasticsearch to index 2 billion documents i.e. all the code files in every repository on the site - across 44 separate EC2 instances, each with two terabytes of ephemeral SSD storage, giving a total of 30 terabytes of primary data. Furthermore, when you hear Microsoft is using it to power Azure Search, a cloud-based search offering, you know you can have confidence that it's a great platform. Now that the introduction is out of the way, let's get started.
Installing Elasticsearch
I won't go into details around how to get Elasticsearch up and running as this has been covered many times before. For the purposes of this post, assume that we have a default installation of Elasticsearch running locally on port 9200.
Defining the model
We need to define the model type to persist to an index in Elasticsearch. An Elasticsearch cluster can contain many indexes where each index can contain many mappings for different types of document. How do we know what properties the suburb model should have? We might have expected to receive a list of the fields contained within the Shapefile as part of the download from the Australian Bureau of Statistics but unfortunately we are only told about the SSC name and code, so we will need to read the Shapefile first to understand the fields available. NetTopologySuite is a .NET port of the JavaTopologySuite, a library for working with geometries which includes, amongst other useful components, a Shapefile reader to read Well-Known-Text (WKT) into geometry types and also a way to serialize those types to GeoJSON (which we'll need later). Reading the Shapefile is straightforward enough
// path to Shapefile
var filename = @"..\..\..\Data\SSC06aAUST_region.shp";
using (var reader = new ShapefileDataReader(filename, GeometryFactory.Default))
{
var dbaseHeader = reader.DbaseHeader;
Console.WriteLine("{0} Columns, {1} Records", dbaseHeader.Fields.Length, dbaseHeader.NumRecords);
for (var i = 0; i < dbaseHeader.NumFields; i++)
{
var fieldDescriptor = dbaseHeader.Fields[i];
Console.WriteLine("{0} : {1}", fieldDescriptor.Name, fieldDescriptor.DbaseType);
}
}
This yields the following
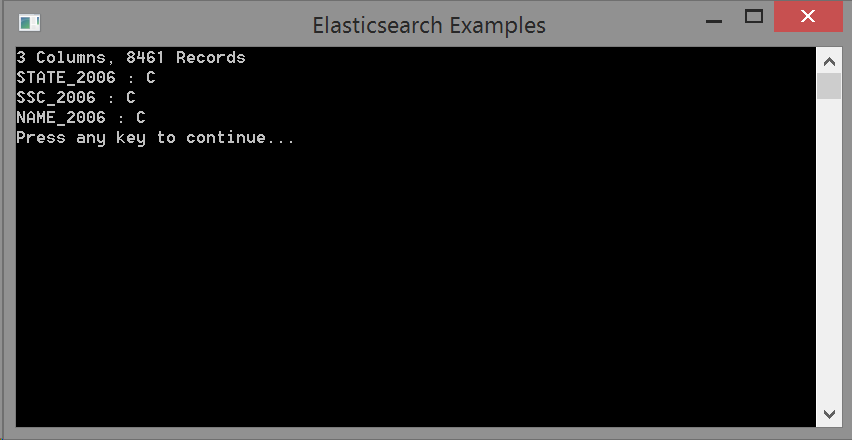
The file has 8461 records and each record has three fields. All three fields are character fields (DbaseType C) and from reading a few records, we see that the STATE_2006 column actually contains a numerical value. With a little detective work to ascertain how the numerical values map to Australian States, we can now define the model for a suburb
public class Suburb
{
public IGeometry Geometry { get; set; }
public int Id { get; set; }
public string Name { get; set; }
public AustralianState State { get; set; }
}
public enum AustralianState
{
NSW = 1,
VIC = 2,
QLD = 3,
SA = 4,
WA = 5,
TAS = 6,
NT = 7,
ACT = 8
}
The Suburb model contains properties for each field found in the Shapefile including the geometry. In addition, the model also contains an Id property which NEST by convention will use as the unique identifier for the document in the index. We'll populate the Id property with the unique SSC_2006 field value as we're indexing the suburbs.
Elasticsearch supports indexing of geometries through the geo_shape type, accepting geometries, features and collections thereof in GeoJSON format. The Geometry property is serialized to GeoJSON by NEST with a custom JSON.Net converter which will need to be registered with the NEST Serializer when a NEST client is created
var connectionSettings = new ConnectionSettings(new Uri("http://localhost:9200"))
.SetDefaultIndex("suburbs")
.SetConnectTimeout(1000)
.SetPingTimeout(200)
.SetJsonSerializerSettingsModifier(settings =>
{
settings.Converters.Add(new GeometryConverter());
settings.Converters.Add(new CoordinateConverter());
settings.Converters.Add(new StringEnumConverter());
});
var client = new ElasticClient(connectionSettings);
It turns out that two JSON.Net converters are needed to serialize IGeometry types, GeometryConverter and CoordinateConverter, so both are registered. The StringEnumConverter is also added so that the AustralianState enum is serialized as a more meaningful string value. The converters could have been added to the model using the JsonConverterAttribute instead of registering with the NEST serializer directly.
NOTE:
NetTopologySuite expects you to use their own derived JsonSerializer to serialize and deserialize geometries to and from GeoJSON. This serializer has all of the JsonConverters registered to correctly handle all of the GeoJSON types. NEST however has its own json serializer which it uses to serialize/deserialize documents as well as queries, commands and results to and from Elasticsearch. Since we don’t want to interfere with NEST’s serialization, we can use only the JsonConverters from NetTopologySuite that we need to serialize geometries to GeoJSON. There are other .NET libraries such as GeoJSON.NET that can work with GeoJSON but it makes sense to use NetTopologySuite here since it's already being used to read the Shapefile.
Now that the model is defined, we need to define a mapping for how the model should be indexed.
Elasticsearch mapping
Elasticsearch and by extension, NEST, support indexing of documents without explicitly supplying a mapping, inferring field names and types from the document input. This can work well for models with simple types but in this particular case, supplying an explicit mapping is required in order to ensure the Geometry property is indexed as a geo_shape type. NEST allows the model mapping for a type to be defined through the use of attributes or through a MappingDescriptor:
public static class SuburbMapping
{
public static CreateIndexDescriptor CreateSuburbMapping(CreateIndexDescriptor indexDescriptor, string index)
{
return indexDescriptor
.Index(index)
.AddMapping<Suburb>(mappingDescriptor => mappingDescriptor
.MapFromAttributes()
.Properties(p => p
.GeoShape(g => g
.Name(s => s.Geometry)
.TreeLevels(10)
)
)
);
}
}
The mapping here has been defined using a MappingDescriptor to keep the concerns of how to map separate from what to map. The .MapFromAttributes() call uses the NEST defaults for mapping the properties of the model e.g. map an int/Int32 property as an integer type in Elasticsearch with a field name the lowercase of the C# type property name. The .Properties() call after .MapAttributes() allows us to override any of the defaults and define additional property mappings; we provide an additional mapping for the Geometry property to be mapped as a geo_shape type, with a field name determined from the property name, Geometry, and a tree level of 10. The tree level defines the precision of the field when performing geospatial queries, with a higher value offering better query precision at the expense of a larger index size on disk, since a greater number of geohashes/quadtrees will be stored in the index. A tree level of 10 using geohashes equates to generating geohashes with dimensions approximately 1.19m x 0.60m which should be more than enough precision for dealing with suburb boundaries.
The mapping above produces the following mapping in Elasticsearch, seen at http://localhost:9200/suburbs/suburb/_mapping?pretty
{
"suburbs" : {
"mappings" : {
"suburb" : {
"properties" : {
"geometry" : {
"type" : "geo_shape",
"tree_levels" : 10
},
"id" : {
"type" : "integer"
},
"name" : {
"type" : "string"
},
"state" : {
"type" : "string"
}
}
}
}
}
}
Now that the mapping is defined, it's time to get indexing!
Indexing with the Bulk API
Elasticsearch provides a bulk api for performing a batch of operations against the index in one API call, making it ideal for indexing multiple documents at a time. We build up a BulkDescriptor and pass this to the Bulk() method on the ElasticClient:
using System;
using System.Collections.Generic;
using System.Diagnostics;
using ElasticsearchExamples.Model;
using Humanizer;
using Nest;
using NetTopologySuite.Features;
using NetTopologySuite.Geometries;
using NetTopologySuite.IO;
using NetTopologySuite.IO.Converters;
using Newtonsoft.Json.Converters;
namespace ElasticsearchExamples.Indexer
{
internal class Program
{
private const int BulkSize = 50;
private const string DefaultIndex = "suburbs";
public static void Main(string[] args)
{
Console.Title = "Elasticsearch Examples";
var client = CreateElasticClient();
client.CreateIndex(indexDescriptor => SuburbMapping.CreateSuburbMapping(indexDescriptor, DefaultIndex));
var filename = @"..\..\..\Data\SSC06aAUST_region.shp";
using (var reader = new ShapefileDataReader(filename, GeometryFactory.Default))
{
var dbaseHeader = ReadShapefileFields(reader);
Console.WriteLine("Press any key to continue...");
Console.ReadKey();
var suburbs = new List<Suburb>(BulkSize);
var stopWatch = Stopwatch.StartNew();
var count = 0;
while (reader.Read())
{
count++;
var attributes = new AttributesTable();
for (var i = 0; i < dbaseHeader.NumFields; i++)
{
var fieldDescriptor = dbaseHeader.Fields[i];
attributes.AddAttribute(fieldDescriptor.Name, reader.GetValue(i));
}
var suburb = new Suburb
{
Geometry = reader.Geometry,
Name = attributes["NAME_2006"].ToString(),
State = (AustralianState)Enum.Parse(typeof(AustralianState), attributes["STATE_2006"].ToString(), true),
Id = int.Parse(attributes["SSC_2006"].ToString())
};
suburbs.Add(suburb);
if (suburbs.Count == BulkSize)
{
IndexSuburbs(client, suburbs);
Console.WriteLine("indexed {0} suburbs in {1}", count, stopWatch.Elapsed.Humanize(5));
suburbs.Clear();
}
}
IndexSuburbs(client, suburbs);
Console.WriteLine("indexed {0} suburbs in {1}", count, stopWatch.Elapsed.Humanize(5));
}
Console.WriteLine("Press any key to continue...");
Console.ReadKey();
}
private static BulkDescriptor CreateBulkDescriptor(IEnumerable<Suburb> suburbs)
{
return new BulkDescriptor()
.IndexMany(suburbs, (descriptor, suburb) => descriptor.Document(suburb));
}
private static IElasticClient CreateElasticClient()
{
var connectionSettings = new ConnectionSettings(new Uri("http://localhost:9200"))
.SetDefaultIndex(DefaultIndex)
.SetConnectTimeout(1000)
.SetPingTimeout(200)
.SetJsonSerializerSettingsModifier(settings =>
{
settings.Converters.Add(new GeometryConverter());
settings.Converters.Add(new CoordinateConverter());
settings.Converters.Add(new StringEnumConverter());
});
var client = new ElasticClient(connectionSettings);
return client;
}
private static void DisableRefreshInterval(IElasticClient client)
{
var response = client.UpdateSettings(settings => settings.Index(DefaultIndex).RefreshInterval("-1"));
if (response.Acknowledged)
{
Console.WriteLine("refresh interval disabled");
}
}
private static void EnableRefreshInterval(IElasticClient client)
{
var response = client.UpdateSettings(settings => settings.Index(DefaultIndex).RefreshInterval("1s"));
if (response.Acknowledged)
{
Console.WriteLine("refresh interval set to 1 second");
}
}
private static void IndexSuburbs(IElasticClient client, IEnumerable<Suburb> suburbs)
{
var bulkDescriptor = CreateBulkDescriptor(suburbs);
var response = client.Bulk(bulkDescriptor);
if (!response.IsValid)
{
if (response.ServerError != null)
{
Console.WriteLine(response.ServerError.Error);
}
foreach (var item in response.ItemsWithErrors)
{
Console.WriteLine(item.Error);
}
}
}
private static DbaseFileHeader ReadShapefileFields(ShapefileDataReader reader)
{
var dbaseHeader = reader.DbaseHeader;
Console.WriteLine("{0} Columns, {1} Records", dbaseHeader.Fields.Length, dbaseHeader.NumRecords);
for (var i = 0; i < dbaseHeader.NumFields; i++)
{
var fieldDescriptor = dbaseHeader.Fields[i];
Console.WriteLine("{0} : {1}", fieldDescriptor.Name, fieldDescriptor.DbaseType);
}
return dbaseHeader;
}
}
}
Finding the right bulk size to send depends on a number of factors including the power of the machines and number of nodes in the cluster, so there can be some trial and error to find the right size for a given scenario. Another thing to consider is that by default, the Elasticsearch index will be set to refresh every one second so that newly indexed data will appear in search results; such a short refresh interval can affect the performance of bulk indexing so if newly indexed data does not need to be searchable until bulk indexing has finished, the refresh interval can be disabled with the following:
var response = client.UpdateSettings(settings => settings.Index("suburbs").RefreshInterval("-1"));
if (response.Acknowledged)
{
Console.WriteLine("refresh interval disabled");
}
And then re-enabled after indexing has finished with:
var response = client.UpdateSettings(settings => settings.Index("suburbs").RefreshInterval("1s"));
if (response.Acknowledged)
{
Console.WriteLine("refresh interval set to 1 second");
}
If indexing is running as expected, we should see output in the console similar to:
You know, for search
Now that we have finished indexing the suburbs, let’s start running some queries. We’re going to be using NEST to write the queries for this post, but for running ad-hoc queries against Elasticsearch there is nothing better than using the JSON based query DSL directly. There are many tools that provide a browser based query interface to Elasticsearch and the two that I have found to work the best for me are Sense (offered as a Chrome extension), a standalone query interface, and Marvel, a plugin that is installed onto an Elasticsearch cluster, offering a query console derived from Sense amongst other tools for monitoring a cluster. For the NEST queries in this post, I will also provide the cURL query equivalent so you can take it and play around with executing them against your own cluster.
Suburb Count
First, let’s count the documents in the index to ensure that all of the suburbs have been indexed:
var response = client.Count<Suburb>();
if (response.IsValid)
{
Console.WriteLine("{0} suburbs", response.Count);
}
/*
curl -XGET "http://localhost:9200/suburbs/suburb/_count"
*/
returns
{
"count": 8461,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
}
}
So far so good, this matches the Shapefile record count. How about a count of suburbs in New South Wales?
var response = client.Count<Suburb>(descriptor => descriptor
.Query(query => query
.Filtered(filtered => filtered
.Filter(filter => filter
.Bool(boolean => boolean
.Must(must => must
.Term(suburb => suburb.State, AustralianState.NSW.ToString().ToLowerInvariant())
)
)
)
)
));
if (response.IsValid)
{
Console.WriteLine("{0} suburbs in NSW", response.Count);
}
/*
curl -XPOST "http://localhost:9200/suburbs/suburb/_count" -d'{ "query": { "filtered": { "filter": { "bool": { "must": [ { "term": { "state": "nsw" } } ] } } } }}'
*/
results in
{
"count": 2593,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
}
}
Looks good too. We needed to use the lowercase string of the State enum as the state field in Elasticsearch is a string type which will have the StandardAnalyzer applied to it, lowercasing the string and removing stop characters. The query uses a term filter however, meaning the input term will not be analyzed and thus taken as is, hence the term needs to be lowercase to match the indexed values for the state field.
Now for something more interesting.
In which Suburb?
Let’s see in which suburb a given latitude and longitude is in
var response = _client.Search<Suburb>(search => search
.Query(query => query
.Filtered(filtered => filtered
.Filter(filter => filter
.GeoShapePoint(s => s.Geometry, geo => geo
.Coordinates(new[] { 151.24397277832031, -33.828786509874291 })
)
)
)
));
if (response.IsValid)
{
foreach (var suburb in response.Documents)
{
Console.WriteLine("Found matching suburb: {0}, {1}", suburb.Name, suburb.State);
}
}
/*
curl -XPOST "http://localhost:9200/suburbs/suburb/_search" -d'{
"query": {
"filtered": {
"filter": {
"geo_shape": {
"geometry": {
"shape": {
"coordinates": [ 151.24397277832031, -33.828786509874291 ],
"type": "point"
}
}
}
}
}
}
}'
*/
results in
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "suburbs",
"_type": "suburb",
"_id": "11681",
"_score": 1,
"_source": {
"geometry": {
"type": "Polygon",
"coordinates": [] // removed for brevity as it's 10,000 lines of coordinates!
},
"id": 11681,
"name": "Mosman",
"state": "NSW"
}
}
]
}
}
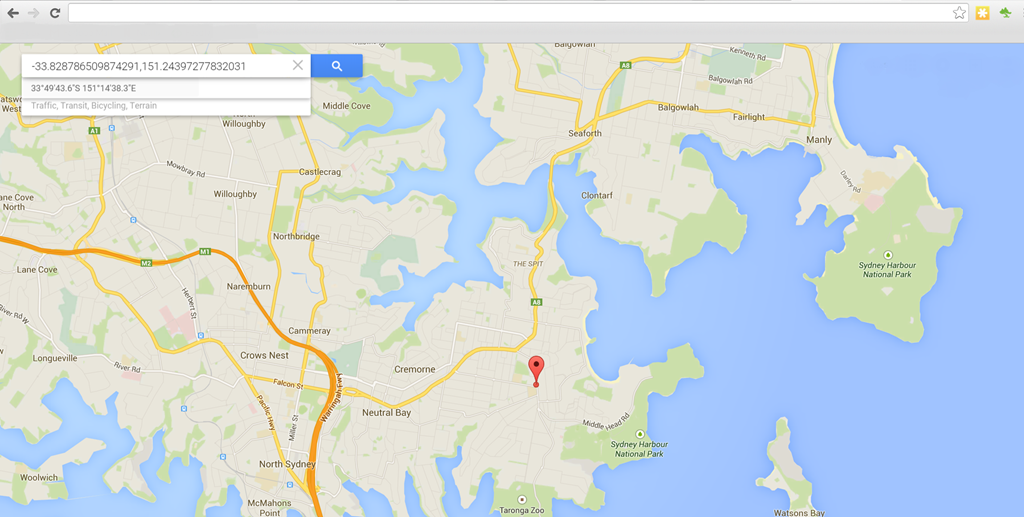
As per the GeoJSON spec, Elasticsearch expects coordinates in the format of [longitude,latitude]. One result is returned, the suburb of Mosman in NSW. Let’s cross-check that against where the latitude/longitude is plotted on Google Maps (notice Google Maps expects coordinates in latitude,longitude format)
Our search looks to align with what is expected on Google Maps, but what would really help is if we could visualize the boundaries of a given suburb on a map.
Suburb Visualization
I’ve put together a demo application to better illustrate our geospatial search. You can click anywhere in Australia on the map and the latitude/longitude of the clicked location is sent to Elasticsearch to find the suburb in which it is located; the suburb data including the geometry GeoJSON is sent back to the client and plotted on the map using the Google Maps API v3. To better illustrate, here is the same search as above in the demo app
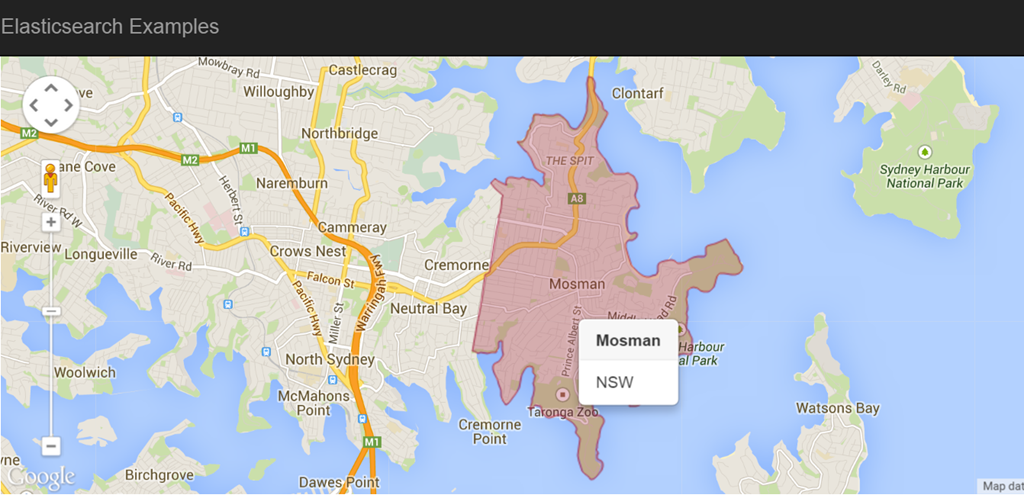
Hopefully I've give you a feel for how geospatial search with Elasticsearch can be used to support many different use cases. In conjunction with the Percolator, you can start doing some really interesting things!